1 Introduction and Motivation
In this era of pervasive computing, computation platforms have extended to small intelligent devices like cell phones, sensors, smartcards, PDAs, etc. As new functionalities and features are being added to these devices, increasing number of applications dealing with significant amounts of data are being developed leading to the need of embedded database support on these devices[Sma]. The queries go beyond simple SPJ queries but still have to be locally computed on the device[BBPV00]. Most of the modern day cell phones are witnessing complex data centric application being developed for them. Sensor networks are also coming up rapidly and these collect data from the environment and subject them to various queries. Most of these queries need to be executed on the device itself to reduce communication costs[MFHH02]. Applications for PDAs execute complicated join and aggregate queries on the device resident data. Thus, there is an increasing need to facilitate execution of complex queries locally on a variety of lightweight computing devices.
However, scaling down the database techniques poses challenges since these lightweight devices come with very limited computing resources. The amount of main memory and stable storage available in such devices is relatively small. Also, the devices are not uniformly endowed with resources, the computing capability and main memory of a cell phone differs from that of a PDA. It is essential that the available resources be utilized optimally for a database system that is developed for such devices.
1.1 Simputer
The Simputer [Sim], developed by
IISC,
The Simputer due to its low cost and sharable features like smartcards is being considerably used in diversified areas. Applications such as E-governance, Microbanking, Health, Agricultural market pricing have to deal with a fair amount of data thereby leading to the necessity of database support for a Simputer. A simple E-governance application will consist of smartcard enabled citizen services like VoterIDs, driving license, ration card, etc. In addition, there will be land and revenue records as well as health care information. The volume of data will be very important and the queries involving selection, projection, joins and aggregates will be quite complex. Hence data collection and processing will involve many complex issues. Applications like Microbanking and Agricultural pricing will involve transactional details. Therefore, transaction atomicity and durability are needed to enforce data consistency. In addition, presence of DBMS will make application development easy and less time consuming.
Due to limited storage capability of the Simputer, it will not be possible to keep all data on the Simputer. Most of the data may be kept in a DBMS that resides on a server. Hence, we need additionally an application that can download the required relations from the server and store them in the Simputer DBMS. This means that we need a synchronizing utility that synchronizes common data between the Simputer and the server.
1.2 Need for Open source and Linux Compatibility
There are two essential factors to be considered in the context of DBMS for Simputer. Firstly, since the Simputer is a low-cost device, the database should be open source. Secondly, since the operating system used in Simputer is Linux, the database system should be Linux compatible. MySQL[MyS], even though it being open source, is ruled out as it is not available in a lighter version. Berkeley DB, another open source database, is available in lighter versions but would not be very efficient as it was primarily designed keeping the powerful servers in mind. Oracle Lite[OLi] and DB2[DB2] Everywhere, lighter versions of Oracle and DB2 are not open source. A new open source and scaled down Linux compatible database system is needed for the Simputer. This has provided us the motivation to develop the open source database since there are no scaled down versions of database in the open market.
1.3 Goal
In a nutshell, our goal is to design a system that will consist of the following components.
· A lightweight relational DBMS that resides on the Simputer.
· An application that can download relations from a server and store them in the Simputer DBMS.
· A synchronizing utility that synchronizes data that is common to both the Simputer and the server.
1.4 What is DELite?
With the above goal in mind, DELite has been developed as an open source light weight database management system, in the department of computer science, IIT Bombay. It has been developed for handheld devices like Simputer. It offers the following features:
· Flash memory is used as read buffer and RAM is used as write buffer.
· A modified two phase optimizer is used to optimize the queires which generates only fully piplined, left deep tree query execution plans.
· Index structures are generated in memory during query execution.
· Select, Project, Join, update and aggregate queries are supported.
· Pointer based storage model like ID-based and Domain based are supported.
This project led by Prof. Krithi Ramamritham is funded by DGF (Development Gateway Foundation). The implementation began in 2003.
The following sections give the technical detail of the DELite project.
2 Database System Architecture
Most of the data in a handheld device will be downloaded from some backup server. Queries will be posed on that data, a few updates will take place and data will be synchronized once the handheld reconnects to the main server. Hence the following modules are the key components of our System.
·
Storage
Manager
The Storage Manager basically consists of different storage models which will reduce the storage cost to a minimum to be able to store more data. Other Storage Manager components include
(a) Compression Module
It keeps the data in compressed form to reduce the space used for storage and for fast query processing.
(b) Transaction Manager Module
It ensures that the database is always in a consistent state.
(c) Access Right Manager Module
It ensures enforcement of security rules in the form of access rights. This module becomes important as the Simputer is sharable and supports Smartcards.
·
Query
Engine
The query engine processes the submitted queries and gives the required result. It requires a Parser the SQL compiler Module, and the Query Processor Module to process the queries.
·
Synchronization
Module
This module is responsible for bi-directional synchronization of data between the Simputer and the remote database. It has to detect and resolve conflicts which result when the same data item is changed on the remote site as well as the PDA.
·
Fetch
Relation Module
It fetches relations from a remote database and stores it in the Simputer database. This module has to decide whether indices should be created for these fetched relations, hence an important part of the system.
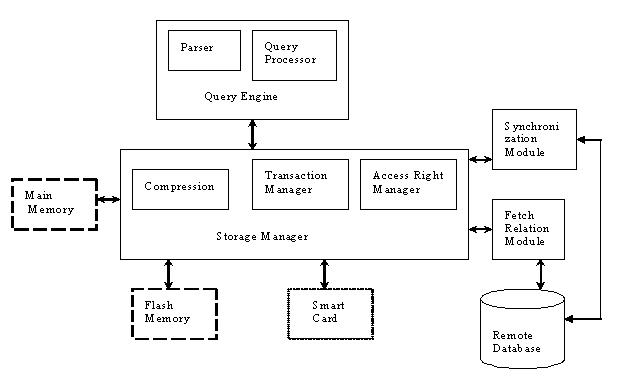
Figure 3.1 System Architecture
3 Database Design
This section discusses about the design issues of different modules and features of the database in detail.
3.1 Storage Manager
The Simputer is constrained by very limited stable storage. The already limited stable storage has to accommodate the operating system as well as the database code, which means even less storage is available to store the data. Storage models designed for such database systems should reduce storage cost to a minimum to be able to store more data. Hence, the storage model and the indexing techniques should lead to compactness in the representation of data as well as indices. Also, since data can be directly accessed from Flash Memory, main memory will be used for doing computations and storing some temporary data.
3.1.1 Existing Models
In this section, we discuss some of the existing storage models that we have adopted and implemented. We have also designed a new storage model that eliminates most of the deficiencies in the existing storage models, which has been discussed in the next section. We have also looked at some of the existing index structures and arrived at the most suitable one for our system. Some of the existing models are discussed below.
·
Flat
Storage
The simplest way to represent relational data is Flat Storage, where the tuples are stored sequentially. The main advantage of this model is access locality. But as discussed earlier, in Flash Memory, sequential access does not perform any better than random access. However, the main disadvantage of this model is that it consumes a lot of space. This is because if any attribute contains duplicate values e.g., Farmer.Ocupation, then the value will be repeated for every tuple.
·
Pointer-Based
Domain Storage
Our storage model should ensure data compactness; hence duplicate values should be eliminated. If any attribute contains duplicate values, the value should be stored only once. This can be done by partitioning the attribute values into domains which are sets of unique values. This has been suggested in [AHK85] [MS83] [PVJ90]. This is known as Pointer-based Domain Storage. The tuples reference the values of the attributes by means of pointers. Since one domain can be shared among multiple attributes, this is a very compact structure. However, the complexity increases in the addition, deletion, and updation of tuples as it may lead to insertion and deletion of values in the domain structure.
- Storage
Cost Evaluation of Existing Models
We compare the storage cost associated with each of the models. We evaluate the cost for an attribute for which we create a domain. For values of L (length of the attribute) less than the size of a pointer p, Flat Storage is definitely the winner as it is more compact than Domain Storage. However, for higher values of L, Domain storage becomes more compact. Hence, depending on the characteristics of data, the system can decide the storage model for each attribute by doing some estimate of these parameters.
We have surveyed the existing storage models, Flat Storage, Domain-based Storage [AHK85], and mentioned advantages and disadvantages of each of them. Now, we propose two new storage models for further compacting data and index representation. We examine and compare all the models based on their storage cost and some properties which impact processing performance.
·
Index
Structures
The things that we need to keep in mind while designing our index structure are
1) The index structures must occupy as less space as possible
2) The indexing model should be efficient and result in faster querying.
Index structures designed for disk resident data aim to minimize the number of disk accesses and minimize disk space. In most of the cases, data values are repeated in the index structures. Hence, those index structures consume a lot of space. However, when data is there in memory, data need not be stored again in index and only pointers to values can be stored.
3.1.2 Proposed model (Id-based Storage)
The model we suggest is inspired by [AHK85]. Our proposed model is based on Domain Storage and we show how we can get rid of the problems faced by earlier models at a slight additional cost. Figure 4.1.2 shows the proposed model.
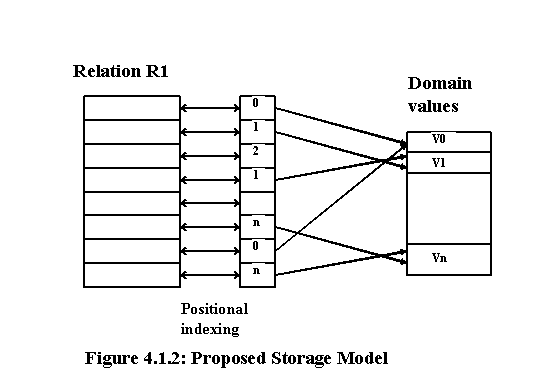
In Domain Storage, we use a pointer to point to the domain value. Instead of having a pointer to point to the domain value, we can keep a distinct identifier for each of the domain values and store the identifier corresponding to the value in the base relation. The identifier of a domain value can be the ordinal value in the domain table. We can then directly use the identifier value as an offset into the domain structure to retrieve the domain value. Hence, we need not store the ID of the values in the domain structure along with the domain values and there is no need for a lookup in the domain structure.
Proposed storage model (Figure 4.1.2) uses extendable IDs, where the length of the identifier grows and shrinks depending on the number of domain values. Initially we take 1 byte to represent each identifier. With a single byte we can represent 28 domain values. When the number of domain values increases beyond 28, one byte will not suffice and we have to increase length of the identifiers by another byte. When the number of domain values exceeds 216, length of the identifiers is increased to 3. In this way, we increase the length of the identifiers only when it is absolutely required. When the number of domain values exceeds 28l where l is the length of the identifier, then l needs to be increased. If the deletions result in the number of domain values becoming less than 28l, then l should be decreased. Thus, the length of the identifier is always élog2D/8ù bytes and hence, the data storage cost is reduced by a considerable extent.
Tuple creation, insertion and deletion for this model will be slightly more complex than Domain storage. However, this small overhead is more than offset by the space efficiency of the scheme
Primary Key-Foreign Key Relationship
Since we are storing pointers in our index, it is space efficient. Addition, deletion or updating of values result in movement of pointers. A primary key is a domain in itself since there are no duplicates. The foreign key values reference the primary key values by their corresponding IDs. The foreign key column becomes a Join Index for the child table and the parent table since for every foreign key value we have the information of the matching parent table tuple. This leads to efficient join of the parent and the child table. Hence, ID-based storage provides a unidirectional join index between foreign key-primary key pair and speeds up joins.
Storage Cost
For a handheld device which deals with very less amount of data, ID-based storage wins over Domain based storage and thus reduces storage cost considerably. We have already seen the conditions in which Domain Storage wins over Flat Storage. When ID Storage outperforms Domain Storage, it can be easily seen that it outscores Flat Storage as well.
·
Bitmap Based Storage
In disk-based systems, bitmap indices are used for efficient querying on multiple keys. A bitmap index is built on a single key. Bitmap indices consume less space when the number of distinct values for which the bitmaps are created is small. We observe that from a bitmap, it is possible to retrieve the tuples of the relation. This forms the basic idea behind Bitmap Based Storage.
In this storage model, a bitmap index is created on the domain attribute. A bitmap is created for each value that the domain attribute can take. Each bitmap has as many bits equal to the number of tuples of the relation. Hence, it serves as an index for the domain attribute. The indices can be used to retrieve the domain values associated with each tuple. Suppose we need the domain attribute value for tuple i. We search examining the bitmaps of each domain value and stop when the ith bit is set. Hence, this scheme also serves as a data storage model.
Bitmaps act as a selection index for the domain attributes, and is the most beneficial when the query is a selection on multiple keys. However, an additional cost has to be borne for projecting out a tuple to its corresponding domain value since we need to traverse on an average half of the bitmaps associated with the domain values.
3.1.3 Performance Properties
In addition to the storage cost, we also looked at the properties [GH90] that affect the performance of the storage manager. These properties are listed below.
Cost to Insert a Tuple: Flat Storage has the most simple and efficient code since only one relation file has to be manipulated. Insertion in Domain and ID Storage is more complex than Flat Storage. Insertion in Bitmap Storage is much more complicated since it involves manipulation of bitmaps.
Cost to Delete a Tuple: Deletion is the easiest in Flat Storage, a bit complex in Domain and ID Storage, and most complex in case of Bitmap Storage. In Bitmap Storage, the length of the bitmap change.
Cost to Update a Tuple: Tuple updation is again cheapest in Flat Storage. For Domain and ID Storage, it gets complicated since new values could be added to domain and old values deleted. Bitmap change is complex in Bitmap storage.
Cost to Project an Attribute: Again, Flat Storage is the winner. Projection in Domain and ID Storage is easy since we have directly the information about the domain value. Projection is most difficult in Bitmap Storage.
Cost to Select a Tuple: When queries are selections on multiple attributes, Bitmap Storage is the most efficient. Selection of tuples is inefficient in Flat, ID, and Domain storage models since they do not involve any index structure.
3.2 Compression
Compression can be used in Database Management System to reduce the space used for storage, faster query processing and reduced bandwidth utilization. These benefits are a tradeoff against additional processing and main memory utilization for compression/decompression process. We have implemented a light weight compression method for Simputer DBMS. As the processing power of a simputer is limited, the compression process should be less demanding. Hence sophisticated compression techniques which are computationally intensive could not be used.
The compression module tries to reduce the redundancy in the stored data in order to achieve reasonable compression while at the same time being light weight with a small memory footprint.
3.2.1 Design
System Architecture: The compression functions are a part of a separate module. This module is integrated with the database. A suitable API for the module is provided that can be used by the system to interact with the module. The system assumes the underlying file storage which is carried forward by the compression module.
Functional Design: The module provides a set of functions that form the compression module which can be used to compress the database. Further operation on the compressed database can also be performed by invoking additional procedures implemented as a part of the compression module. The system provides functions for compressing/decompressing relations. It also provides functions as addition, deletion and display for the compressed relation.
Data Design: The earlier DELite system used a fixed length record format for storage of flat relations. In case of fixed length records the system assumes the worst case length of an attribute. Hence lot of storage space is wasted in form of null characters. Variable length records can be used in order to save space by eliminating null characters. The compression module uses the concept of variable length record in order to reduce storage space wastage. The variable length records require the storage of record offsets as a part of relation metadata.
3.2.2 Compression Algorithm
The compression module performs compression at two levels.
· All the null characters are eliminated from the fixed length records.
· The record is compressed using LZ77, a dictionary based compression algorithm.
NULL Character Elimination
The elimination of NULL characters in the record before the tuple compression improves the compression ratio. Otherwise the LZ77 compression algorithm also encodes the NULL characters considering them to be useful data which reduces the compression gains.
LZ77 Algorithm
The principle of the LZ77 compression algorithm is to store repeated occurrences of strings as references to previous occurrences of the same string. The point is that the reference consumes less space than the string itself, provided that the string is long enough. The coder uses a brute force approach to find string matches in the history buffer. The decompression is very fast, and the compression ratio is often very good. The reference to a string is coded as a (length, offset) pair, where the length indicates the length of the string, and the offset gives the offset from the current data position. To distinguish between string references and literal strings (uncompressed bytes), a string reference is preceded by a marker byte, which is chosen as the least common byte symbol in the input data stream (this marker byte is stored in the output stream as the first byte).
Occurrences of the marker byte in the stream are encoded as the marker byte followed by a zero byte, which means that occurrences of the marker byte have to be coded with two bytes. The lengths and offsets are coded in a variable length fashion, allowing values of any magnitude (up to 4294967295 in this implementation).
3.3 Transaction Management
We have implemented a transaction manager which has two parts: Concurrency Control and Recovery. Almost Serial protocol has been implemented for Concurrency Control. Recovery protocol is yet to be developed.
3.3.1 Concurrency Control
For the concurrency control, we have implemented a Serial Protocol. Details of the algorithm are given in the paper named “An Almost Serial Protocol for Transaction Execution in Main Memory Database Systems" by Stephen Blott and Henry F. Korth, VLDB 2002. ( [BK02] in References Section). In this protocol it is assumed that each transaction is executed by one process only. A single mutex is used to ensure exclusion of database mutex, any other process requesting the mutex is blocked, at least until the first process releases it. Locking is at the database granularity level.
3.3.2 Recovery
To be done.
3.4 Security
Data security implies protection from malicious attempts to modify or steal the data. Our goal is to implement user authentication and to add access right and privileges at the relation level.
3.4.1 Design
To use DELite database system, user has to login first. User is first authenticated based on his password. Only ADMIN has permission to create new users. Passwords are encrypted before storing in table and only ADMIN has permission to view this table.
When the catalog is initialized, all the existing tables are deleted and new tables are created. New table USER_PASS holds only one user ADMIN and his/her password. ADMIN can then create new users, roles and tables and assign permissions.
After a query is parsed, it is executed only after confirming that the user has appropriate permissions for that query. The permission can be given to the user directly or to a role which is then assigned to the user. One has to check both to determine whether user has the permission to execute the query.
A person who has created a table has all the permissions on that table. He can then grant permissions to others (recursive grant). ADMIN by default has all permissions on all the tables. A user can be given permission to grant permissions to others.
When permission is revoked from a user, it should be revoked from all the users he gave that permission to (recursive revoke).
The following tables are used.
· USER_PASS: It holds the user name and its encrypted password.
· ROLE_USER: Holds different role in the system and the user which is assigned that role.
·
USER_PERM: All the access information is stored
here. The different attributes are Granter, Grantee, Table Name,
3.4.2 Queries Implemented:
1) Add user : CREATE USER username IDENTIFIED BY password;
2) Delete user: DELETE USER username;
3) Change password: CHANGE PASSWORD username oldpassword newpassword;
4) Create role: CREATE ROLE rolename;
5) Delete role: DELETE ROLE rolename;
6) Assign role: GRANT rolename TO username;
7) Revoke role: REVOKE rolename FROM username;
8) Grant permission:
a) GRANT [INSERT/UPDATE/SELECT/DELETE/SHOW/DROP/ALL] ON tablename TO username [WITH GRANT OPTIONS];
b) GRANT [INSERT/UPDATE/SELECT/DELETE/SHOW/DROP/ALL] ON tablename TO rolename [WITH GRANT OPTIONS];
9) Revoke Rermission:
a) REVOKE [INSERT/DELETE/UPDATE/SELECT/DROP/SHOW/ALL] ON tablename FROM username;
b) REVOKE [INSERT/DELETE/UPDATE/SELECT/DROP/SHOW/ALL] ON tablename FROM rolename;
Details of Grant and Revoke Queries:
GRANT Command: GRANT command gives specific privileges on a specified table to one or more user(s)/role(s). These privileges are added to those already granted, if any. If WITH GRANT OPTIONS is specified, the recipient user/role of the privilege may in turn grant it to others (recursive grant). Without a grant option, the user/role cannot do that. There is no need to grant privileges to the owner of the table (the user who created it), as the owner has all privileges by default. The table owner can revoke these privileges. The possible privileges are:
SELECT: Allows SELECT from any column of the specified table.
INSERT: Allows INSERT of a new row into the specified table.
UPDATE: Allows UPDATE of any column in the specified table.
DELETE: Allows DELETE of a row from the specified table.
All: Grant all the above privileges at once.
REVOKE COMMAND:
The REVOKE command revokes previously granted privileges from one or more user(s)/role(s). If a user/role holds a privilege WITH GRANT OPTION and has granted it to other users/roles then the privileges are recursive grant privileges. If the privilege held by the first user/role is being revoked and recursive grant exists, those recursive privileges are also revoked. A user/role can only revoke privileges that were granted directly by that user/role.
3.5
Query
Engine
Query engine has two modules. One is query processor and the other is paresr. Query is submitted to the query engine. Paresr module checks the query for correct syntax and creates a query tree. Query processor has two stages: query optimizer and query executor. The query optimizer takes the query tree created by parser and generates a query plan which will be the input to the query executor. Query executor recursively goes through the plan tree and retrieves the rows by making use of the storage system while performing joins and aggregates and finally gives the result. In the following sections we will discuss about these modules in detail.
3.5.1 Parser
The parser checks the query string for
valid syntax. If the syntax is correct a parse tree is built up and handed back
otherwise an error is returned. For the implementation, Linux tools lex and yacc are used.
The parser defined in parser.y and in parser.l
is built using the Linux tools yacc and lex.
The lexer is defined in the file parser.l and is responsible for
recognizing identifiers, the SQL keywords etc. For every keyword or identifier
that is found, a token is generated and handed to the parser.
The parser is defined in the file parser.y and consists of a set of
grammar rules and actions that are executed whenever a rule is fired. The code
of the actions (which is actually C-code) is used to build up the parse tree.
The file parser.l is transformed to the C-source file lex.yy.c using the program lex
and parser.y is transformed to parser.tab.c using yacc. After these transformations have taken
place a normal C-compiler can be used to create the parser. We don’t need to
make any changes to the generated C-files as they will be overwritten the next
time lex or yacc
is called. The mentioned transformations and compilations are normally done
automatically using the makefiles.
3.5.2 Query Processor
Once the parser generates the query tree, processing of a query is done in two stages: query optimization and query execution.
For the query processing techniques, RAM is the most critical resource in lightweight computing devices. Writes to flash memory are very costly. Hence, the query processing schemes should minimize materialization in secondary storage. If read/write ratio is very high we can use flash memory as write buffer, otherwise main memory should be used as write buffer. The main memory limits the query execution capabilities in a small device; hence the techniques should make optimum usage of the memory.
1.
Query Optimizer
The Optimizer creates an optimal
execution plan. A given SQL
query (a query tree) can be executed in different ways, each of which will
produce the same set of results. The query optimizer examines the cost of each
of these possible execution plans, selecting the execution plan that is cheapest
and expected to run the fastest.
Features Desirable in a Query Optimizer
Following are the features desired in query optimizer for memory constrained devices.
·
Cost
Based Query Optimization
Cost-based query optimizer should be taken since only cost-based approach can ensure the best execution plan. Queries should be optimized based on the memory and execution time profiles of the operator schemes.
·
Left Deep
Tree Query Plan
Since query processing should minimize writes to secondary storage, materialization of intermediate results should be minimized. Materialization, if absolutely necessary, should be done in main memory. All these constraints favour the use of left deep tree as the query plan tree since all other query plans resort to some materialization. Left deep tree is most suited for pipelined evaluation, since the right operand is always a stored relation, and thus only one input to each operator is pipelined.
·
Optimal
Memory Allocation
When we have a fully pipelinable schedule, we cannot assume that the entire memory is available for all the operators [HSS00]. This problem is crucial since handhelds are constrained by very less memory. Memory has to be shared optimally among all the operators. The amount of memory available in handhelds is increasing with every new device. Therefore, we need to have a strategy that guarantees the best query execution plan for every device depending on the main memory available.
·
Complex
Queries
Existing approaches for query processing in small devices [BBPV00, BPA03, KLLP01, SG00] use minimum memory algorithms for every operator thus minimizing the usage of memory. This can lead to a very poor performance for queries involving complex joins and aggregration over several relations. Execution time for complex queries can be reduced by using operator algorithms which build in memory indeces and save the aggregate values. The operator order also plays a crucial role since it determines the size of the subtree over which the iterators operate.
·
Storage
Models
The underlying storage models used to store the relations also influences query processing. The cost of selecting and projecting a tuple is different for each storage scheme. The cost of query execution plan depends on the selection and projection costs and hence will vary across storage schemes.
Thus the memory and storage model cognizant query plan is essential. Also, query optimizer itself should not be too complex to be executed on the handheld devices. Figure 2.2 characterizes the requirements of the database system. The system should select the storage model based on data characteristics and the expected type of query. For any query q, depending on the storage model and amount of available memory, the optimal query processing should be determined.

3.5.3 1- Phase and 2- Phase Optimization
There are two approaches to solve the memory allocation problem. 1-phase approach and 2-phase approach. In 1-phase approach, the optimizer takes into account division of memory amongst operators while choosing between equivalent plans. In the 2-phase approach, the query is first optimized and an optimal query plan is found. Then, the division of memory amongst the operators is done. The 2-phase approach is able to optimally divide the available memory amongst the operators of a given plan, the plan being considered may itself be suboptimal for the available memory. 2-phase approach has lesser complexity and is suitable for handheld devices. However we have implemented both 1-phase optimizer and 2-phase optimizer with modification.
Modified 2-phase approach is needed for handhelds. In two phase approach, while determining the optimal plan in phase -1, maximum memory is assumed to be available for all the operators. This may not be true for the resource constrained device limited by main memory. Some of the operator schemes may not be feasible. For the limited memory device, depending upon the available memory, we need to determine the best scheme for every operator out of all feasible ones. So, the scheme chosen in phase-1 and in phase-2 need not be the same.
3.5.4 Cost Based 2-Phase Query Optimizer
Cost-based approach can ensure the best execution plan. Our query Optimizer is a cost based 2-phase optimizer with modification in which query execution plan takes the shape of a left deep tree, the optimal operator order is evaluated using the System-R dynamic programming approach [SACL79]. The steps are as follows.
1) In phase-1, it determines the operator order using the System-R dynamic programming approach by choosing the least cost scheme for every operator. And
2) In phase-2, it divides memory among the operators and based on the (memory, execution time) profiles of the operator schemes, choose the scheme appropriate for an operator given the memory allocated to it.
The schemes for evaluating an operator use different amount of memory and have different cost. All the schemes take care of the fact that left deep tree is used as query plan and can be implemented using iterator Model[Gra93]. The schemes for join operator include nested loop, index nested loop, hash join and join using join index. For aggregation we have nested loop aggregation and buffered aggregation where we store the aggregate values. Every operator scheme is characterized by a benefit/size ratio, which represents the benefit of the scheme per unit memory allocation. An operator is defined by the benefit and size of each of its schemes.
·
Exact
Memory Allocation (Two Phase Approach)
[HSS00] propose a 2-phase exact solution to the memory allocation problem. In phase 1, the scheme for every operator is determined. In phase 2, the cost functions of all the operator schemes are used to divide the memory among all operators. For optimal allocation of memory among n operators, it merges the cost functions of two operators and forms a superoperator cost function. The superoperator cost function stores the optimal division of memory along with the cost value for each memory division point. Then this combined cost function is merged with the cost function of the third operator to get combined cost function of the three operators. In this way, all operator cost functions are merged into a single cost function and then memory division is done by tracing back the steps for each intermediate plan.
The exact solution can be used in our system with some modifications. The schemes for every operator should be determined in phase 2, hence memory need to be divided among the operator cost functions rather than the cost function of an operator scheme. The operator cost functions are piecewise linear functions and hence we can use the exact memory allocation algorithm by replacing the scheme cost functions with the operator cost functions. The scheme for an operator is decided based on the memory allocated to it. The amount of memory allocated to an operator will exactly match with one of its schemes. However since the time and space complexity of the exact algorithm can prevent it from being used in some devices, we have developed a heuristic solution with a reduced complexity based on the benefit of an operator per unit memory allocation.
·
Heuristic
Memory Allocation (Modified Two Phase Approach)
Given the available memory, we use a heuristic to determine which operator gains the most per unit memory allocation and allocate memory to that operator. The gain of every operator is determined by its best possible scheme. We repeat this process until all the operators have been allocated memory. Our heuristic is as follows:
Select the scheme that has the maximum
benefit/size ratio and allocate its memory.
The procedure MemAllocate which allocates the memory, takes the memory available as input Mtotal to evaluate the query and allocates memory to all the operators. It makes use of procedures GetBestScheme, RemoveSchemes and RecomputeBenefits. Mmin is the minimum amount of memory that is required to execute the plan. Initially we select the minimum scheme for every operator and reserve Mmin amount of memory, this guarantees the execution of the plan. Memory that remains after allocating Mmin is then divided optimally among all the operators. At every step of the algorithm, the amount of memory to be allocated is Mavail. The procedure GetBestScheme takes the current available memory Mavail as input and outputs the best scheme sbest and its corresponding operator obest. We allocate the required memory to the best scheme, i.e. Memory (sbest) to the operator obest and recompute Mavail accordingly. We throw away sbest and all the schemes of obest which need less memory than Memory(sbest ) and recompute the benefit and size values for the other schemes(which need more memory than Memory(sbest ). If no best scheme has been returned it means that memory allocation is over and the procedure returns.
3.5.5 One Phase Query Optimizer
We are given n operators and their piecewise linear functions, along with available memory and we need to compute the optimal memory for each operator. The OptMerge algorithm is used for the same. It processes two operators at a time and tries to find their optimal memory division. Since the cost functions are all piecewise linear cost function, testing is done at changeover points. Left deep tree execution order is considered
The one phase optimizer has to input a query, examine all possible execution plans for the execution of that query and select the overall cheapest one to be used to generate the answer of the original query. Steps are as follows:
1). Determine the complete query DAG for the input query. Each path in the DAG will produce the same output but at different cost.
2). Determine the optimal division of available memory between the various operators in the query.
3). Determine the optimal implementation choices such as the join order for evaluating each subexpression in the query. This is related to the physical schema of the database.
4). Find the cost associated with the step 1 and step 3. A formula is used to fine the cost of each join method access type and in general every distinct step that can be found in the execution plan.
5). Find the execution order and algorithm which minimizes the cost - this is the final optimized query.
We have implemented both the optimizers and carried out performance analysis. Results show that 2-phase optimizer performs better than 1-phase optimizer.
2.
Query Executor
The Executor
takes the plan given by the Optimizer and recursively processes it
to extract the required set of rows. The executor is used to evaluate the SQL
query types: SELECT and AGGREGATE. It makes use of the storage system
while scanning relations, performs joins, evaluates qualifications
and finally returns the rows derived.
3.6 Synchronization
To be done
3.7 Fetch Relation Module
To be done
4 Implementation Details
4.1 The Directory Structure
The system is being developed using the C programming language. The codebase is distributed over several subdirectories which form a tree structure (Figure 9.1). The backend database code is present in simpdb/src/backend and the include files in simpdb/src/include. Recursive makefiles are used in every subdirectory to build the system. The tools lex and bison have been used to write the SQL parser.
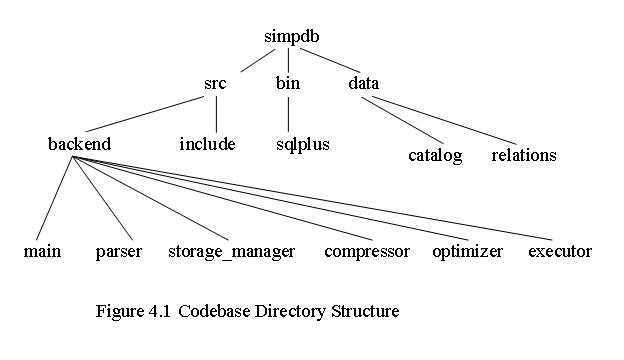
Details of all the modules are as follows.
·
Storage
Manager
The storage manager code contains the functions which deal with the storage manager interface with the system catalog. Also it implements the functions which read and write the tuples from the database. All the storage models use single catalog file. The storage manager further divides into subdirectories which contain functionalities of the respective storage model. The storage models Flat storage, Domain storage, and ID storage have been integrated presently. In addition, ID based Join Index model has also been implemented. The data types that are being currently supported are INTEGER, FLOAT, and CHAR. CREATE TABLE and INSERT statements are fully supported with the above data types. Security module is also integrated as part of storage manager module.
·
Compression
The compression code is present in the directory compression. commonfunction.c contains common functions used by the compression functions. compress.c file implements functions to compress relations and to insert new tuples into the relation. decompress.c file implements functions to decompress relations and to fetch compressed tuples from the relation. lz.c Implements the LZ77 compression algorithm. It is done for flat storage model.
·
Query
Optimizer
The query
optimization code is present in the directory optimizer/1phaseoptimizer. The optimal operator order is found out
using a dynamic programming algorithm. This is being used to determine the
query execution plan. The code for operator order determination is available in
bestplan.c. We have implemented the
exact allocation algorithm as well as the heuristic allocation algorithm. The
code for memory allocation is present in memalloc.c.
·
Query
Executor
The query execution code is present in the directory executor. The operators select and project have been implemented fully. Nested Loop Join, Indexed Nested Loop Join, and Hash Join have been implemented. All the operators have been implemented using the iterator model. Among the aggregate operators, the COUNT operator has been implemented using the nested loop and the buffered approach. The rest of the aggregate operators, AVG, MIN, MAX, SUM are being implemented. All types of SPJ queries are supported along with the COUNT operator.
4.2 Building the system and Sqlplus
To build the system, go to the directory simpdb and run the makefile present there. The recursive makefiles inside the directories are executed in turn and finally the SQL parser is build in the directory simpdb/bin. The SQL parser takes SQL statements from command line as well as from files and executes them.
4.3 Code Related Information
4.3.1
How to
install?
In Linux machine: First download the code in your directory . Code contains directory path at few places which need to be changed to your home directory path:
· In file simpdb/src/Makefile.global change the path /home/xxx/... to your home directory path.
· In file simpdb/src/include/catalog/flat_catalog/catalog.h change /home/xxx/..... to your home directory path.
In Simputer: Switch on the simputer by
pressing power button. Attach the provided serial cable to it. The other end goes to a free port on your host Linux Machine. Log on as root in host machine. Using the communication
program (we use `minicom') - you have
to first configure the program so that it uses host machine with communication speed
set to 115200 (that's what the Simputer manual says), and 8N1 format, hardware
and software flow controls disabled. Doing this with minicom is very simple -
invoke it as:
minicom -m -s
It
will ask to configure. By pressing yes will give the configuration table in which
you need to setup the following.
Bits: 115200 8N1
F
and G should be set to NO.
Then boot the simputer. You will see the login prompt. You should be able to type in a user name/password and log on. You should be able to run simple commands like `ls', `ps' etc - you may even be able to use `vi'.
Setting Up the
1. Make sure you have a recent Linux distribution - Red Hat 7.3 is good enough.
- Plug one end of the USB cable onto the
USB slave slot in the Simputer, then boot the Simputer.
- Boot your Linux PC. DO NOT connect the
other end of the USB cable to your PC now. Log in as root on the PC. Go
to /sbin directory.
- Run the command `insmod usbnet' to
load a kernel module which enables USB networking on the Linux PC.
- Verify that the module has been loaded
by running `lsmod'.
Now
plug the other end of the USB cable onto a free USB slot of the Linux PC. The
USB subsystem in the Linux kernel should be able to register a device attach.
Run a few more commands:
1.
Run `ifconfig usb0 192.9.200.1' - this will
assign an IP address to the USB interface on the Linux PC.
2.
Using `minicom' and the supplied serial cable,
log on to the Simputer as root. Then run the command `ifconfig usbf 192.9.200.2' on the Simputer.
3.
Try `ping 192.9.200.2' on the Linux PC. If
you see ping packets running to and fro, you have successfully set up a TCP/IP
link!
You can now telnet/ftp to the Simputer through this TCP/IP
link.
In Windows: We have developed the WINDOWS
version of code also. We have used Bloodshed Dev-C++, version 4.9.9.2. for compiling
the code.
1. First download the code in desired directory. Open the code using Dev-C++.
2. Go to Project options->Directories->IncludeDirectories. Add the path of header files "(xxx\delite\simpdb\src\include".
3. Now we need to do some changes in code. IT IS SAME AS “Install in Linux section".
4.3.2 How to compile and run the code?
In Linux:
"lex" and "bison"
tool for parser are required in the machine before compiling the code. To
compile the code go to the directory "simpdb" then type
"make" and enter. Once the code is successfully compiled, go to the
directory "bin". To run in
Simputer, first cross compile the
code in Linux machine. Then move the bin and parser directory (initdb.exe is created in bin and sqlplus.exe in parser
directory) in the simputer.
Now you will be in simpdb/bin/
Write "./initdb.exe" and press enter: initial catalogs will be created.
Write "./sqlplus.exe ../examples/create.sql" and press enter. All the SQL files are there in examples directory and can be run by using this command.
In Windows: Once the code is downloaded and required changes are done we can compile the code using Execute->rebuild options.
To run the code: The initdb.exe and delite_proj.exe (exe with the name of project) will be created in delite folder. “initdb.exe” will initialise all the catalogs. (It has to be done first time only). We can run queries using “delite_proj.exe”.
D:\delite> initdb.exe
D:\delite> delite_proj.exe <enter>
<write sql query> or we can give queries through file like
D:\delite> delite_proj.exe filename
4.3.3 UNICODE Data
UNICODE support for Hindi and Marathi (Indian) Languages has been provided. Now Hindi and Marathi data can be stored in our database system. To write in Hindi/Marathi ( Devnagiri script), Devnagiri fonts are required which can be downloaded from the site “http://aaqua.persistent.co.in/aaqua/forum/index “. After writing the data in a file, the file should be saved as UTF-8.
4.3.4 SQL Support in DELite
SQL WORKING: Following is the list of SQL statements working in DELite code.
- CREATE TABLE tablename(col1, col2...) with data types int, float and char(n);
- INSERT INTO tablename VALUES (......);
- DROP TABLE tablename;
- SHOW TABLE tablename [WHERE whereclause/LIKE]; ** without Joins.
- SHOW TABLES ; (lists all the tables present in database)
- SELECT *[column_names] FROM tablenames [WHERE condition[AND condition...]];**with joins
- UPDATE tablename SET setclause[AND/OR setclause] WHERE whereclause[AND/OR whereclause];
- DELETE FROM tablename [WHERE whereclause[AND/OR condition]];
- COMPRESS TABLE tablename;inserting, deleting and listing of tuples can be done in compressed table.
- DECOMPRESS TABLE tablename;
- UPDATE tablename SET value[AND/OR] WHERE match_condition IN query;
- ALTER TABLE tablename RENAME TO new_tablename;
*** All the above SQL working fully for flat storage type.
PROPOSED PROJECTS: Following is the list of items to be added in DELite code.
· Support for nested subqueries.
· Primary and secondary index support on all the storage managers and on
compressed data.
· Buffer management for compressed and uncompressed data.
· Updating whole column with a given expression eg., UPDATE book SET
price=price*1.5; comparison with >/< .
· Alter table functionalities (add column, Remove columns, Change column data
type, Rename column etc).
· COMPRESS and DECOMPRESS in Domain-based and Id-based storage-
manager. Features like INSERT, SHOW, DELETE, UPDATE after compressing
the table.
· Querying after compression.
· SELECT with JOIN for Domain based storage.
· Aggregate Operators (AVG, MIN, MAX, SUM).
· UPDATE in Domain-based storage
WORK IN PROGRESS: Currently we are working on the following.
· SELECT with JOIN in ID-based storage.
· UPDATES after COMPRESS in flat storage.
· WE HAVE DEVELOPED THE WINDOWS VERSION OF DELite CODE. Also, We have provided the UNICODE Support to store Hindi and Marathi data in our database system.
***code has readme and status files which give the detail information about the code.
4.3.5 Coding Standard
We have followed the coding standard guidelines listed below.
· Each file has general description of program at the begining.
· Every function has the following details: name of code developer, date, version, description of function, input and output parameters.
· Meaningful name are given to functions, variables to make it easy to understand and follow.
· Every directory has a README file, which contains general description of each file in that directory.
· Every directory has a Makefile.
· Code: Indent either 4 or 8 blank spaces. Proper Format has been followed for loops and block statements.
· Code is well documented.
Appendix
1. Rajkumar’s Thesis for details of Storage and Query Processing.
2. Report on Compression for details of implementation.
3. Report on One Phase Optimizer for details of implementation.